One of the biggest challenges in data analytics is managing and transforming large amounts of data across multiple sources. This is where AWS Glue comes in. AWS Glue is a fully managed extract, transform, and load (ETL) service that simplifies the process of moving data between data stores. In this comprehensive guide, we will take a deep dive into AWS Glue and explore its key features, benefits, and use cases. We will also compare it with traditional ETL tools to illustrate its advantages. If you’re curious about AWS Glue and want to learn about its functionalities and capabilities, read on.
What is ETL?
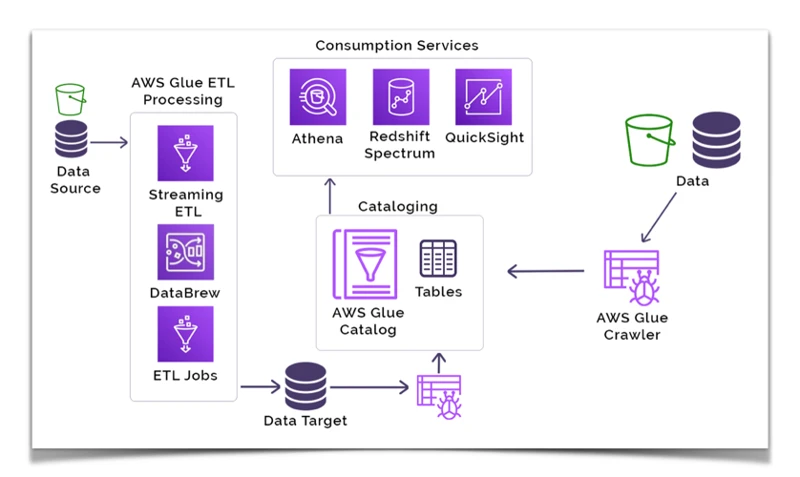
ETL or Extract, Transform, Load is a process used in data integration to extract data from various sources, transform the data into a structure that’s suitable for analysis, and load the transformed data into a target destination. This process is crucial in modern data management and analysis, where data is spread across multiple sources and requires complex transformations to be usable. In the following sections, we’ll dive deeper into each step of ETL and explore how Amazon Web Services’ AWS Glue simplifies this process. So, let’s get started without any delay!
Extract
During the ETL process, the first step is “Extract”, which is the process of extracting data from various sources such as databases, flat files, and other data sources. The data sources can be on-premises or in the cloud. The data is extracted in the form of structured, semi-structured, or unstructured data. The extracted data can be in different formats, such as CSV, JSON, Parquet, Avro, and more.
Extract Process Steps:
| Step | Description |
|---|---|
| Determine the data source | In this step, you need to determine the data sources that you want to extract data from. These sources can be flat files, databases, or other sources. |
| Connect to the data source | You need to establish a connection to the data source to fetch the data. You can establish a connection using different protocols and APIs. |
| Extract data | After connecting to the data source, you can extract the data based on some predefined criteria such as SQL query or NoSQL query, data filters, or other criteria. |
| Store data | Once you have extracted the data, the data needs to be stored in a staging area so that it can be processed in the next step. |
AWS Glue provides four ways to extract data from different sources: Glue ETL jobs, Glue crawlers, AWS Database Migration Service, and AWS Snowball. Glue ETL jobs provide the flexibility to extract data from different sources and transform the data according to the business requirement.
Glue crawlers help extract metadata from the source data to create a data catalog that can be used for mapping data to the target destination. AWS Database Migration Service is used for extracting data from on-premises data sources and migrating that data to the AWS cloud. AWS Snowball is a petabyte-scale data transport solution that helps to get data into and out of AWS.
Now let’s move on to the next step of the ETL process which is “Transform”. For more information on AWS Glue, please refer to this article.
Transform
During the ETL process, the next step after extraction is transformation. This step involves manipulating the extracted data to make it suitable for the target data store or data warehouse. It mainly includes data cleaning, data mapping, data conversion, filtering, and aggregation. Transformation is a crucial step since it cleans up any inconsistencies in the data, resolves redundant data, and updates the data to the required schema. There are various transformation types that can be applied to the data, including:
- Filtering: This involves removing or keeping specific data based on a particular criteria from the extracted data set.
- Mapping: This involves converting the data values to a different format for usage in the target data store.
- Normalization: This involves restructuring the data to eliminate redundancy, ensure data consistency, and improve data integrity.
- Aggregating: This involves combining the data to form a summary of a particular category or group.
- Joining: This involves combining data from two or more sources based on a particular identifier to form a single data set.
- Validation: This involves verifying the data to ensure it conforms to a specific set of rules or guidelines.
Transformations can be performed using different tools and programming languages, such as Python, SQL, and Java. AWS Glue provides built-in transformations such as join, pivot, and relationalize to help transform your data efficiently.
For example, suppose you have data in different formats and need to extract it and bring it together in a unified format. You can use AWS Glue to transform the data to create a standardized schema for the data to be combined in the target data store or data warehouse. With AWS Glue, you can perform these transformations without having to worry about the underlying infrastructure or data management tasks.
If you need to enhance your glue projects more with proper knowledge about glues and their features you can check out how to make PVA glue article.
Load
When it comes to loading in ETL, the transformed or modified data is finally put into a new location like a data warehouse or a data lake. This is the last step of ETL which completes the cycle and makes the data ready to use. In the loading phase of AWS Glue, you can choose your target data storage from a variety of options like Amazon S3, Amazon RDS, Amazon Redshift, and more. AWS Glue uses JDBC and ODBC drivers to connect to the data storage and apply the transformations.
Amazon S3 is the most commonly used data storage in AWS Glue, due to its cheap storage and ease-of-use. S3 is an object-based storage service and Glue can easily read data from and write data to S3. AWS Glue also provides a feature called partition projection which helps in improving the query performance while querying large datasets stored in S3.
Amazon RDS is a managed relational database service provided by AWS which is also used as a target for AWS Glue loading. AWS Glue can load data into a variety of AWS RDS databases such as MySQL, PostgreSQL, Oracle, and SQL Server. Loading data through AWS Glue into Amazon RDS is a simple and easy-to-use process that requires minimal configuration.
Amazon Redshift is another popular target data storage for AWS Glue loading. It is a fast, cost-effective, and scalable data warehouse solution provided by AWS. AWS Glue can easily load data into Redshift from various sources like S3, Amazon RDS, and more. AWS Glue automatically integrates with Amazon Redshift, which means you can quickly start loading data into Redshift without any additional setup.
Whether you choose Amazon S3, Amazon RDS, Amazon Redshift, or any other storage solution, AWS Glue makes the loading process simple and streamlined. With just a few clicks, you can configure your target data storage and load data effortlessly.
(internal link: /how-long-should-elmer-wood-glue-dry/)
What is AWS Glue?
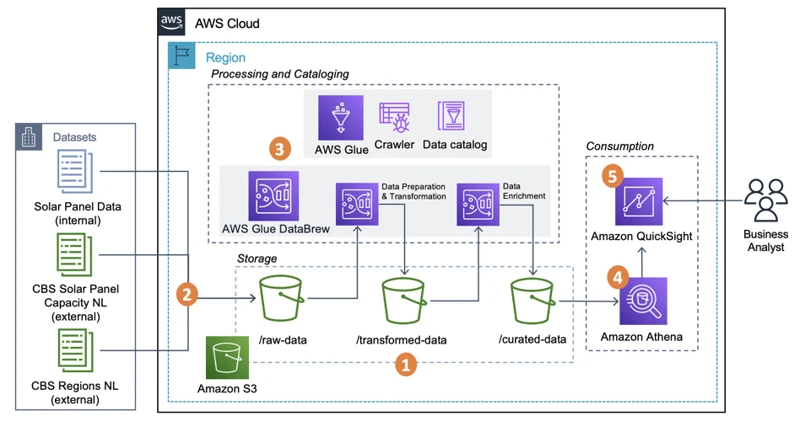
AWS Glue is a fully-managed Extract, Transform, Load (ETL) service that makes it easy for you to move data between data stores. But what exactly is ETL? ETL is a commonly used data integration process that involves three major stages, Extract, Transform, and Load. It is used to consolidate data from different sources, so it can then be analyzed. In this section, we will dive deeper into AWS Glue and explore its key features, how it works, its workflow, and its benefits over traditional ETL tools. So, if you’re ready to learn more about the power of AWS Glue, keep reading!
Key Features of AWS Glue
AWS Glue is an ETL service that has various features that set it apart from traditional ETL tools. Here are some key features of AWS Glue:
- Auto-Discovery: AWS Glue automatically discovers data, its format, schema, and dependencies and populates the Glue Data Catalog with these metadata details. This significantly eases the process of managing and accessing data sources for ETL jobs.
- Data Catalog: The Data Catalog provides a central repository to store, maintain, and version control the metadata of data sources, ETL jobs, and development workflows. It also enables you to search and explore your data sources, their schemas, and dependencies.
- Serverless Execution: AWS Glue automatically provisions and scales the required infrastructure to execute ETL code and manage its dependencies. You don’t have to worry about deploying and managing servers, or configuring and optimizing the infrastructure for ETL workloads.
- Flexible and Extensible: AWS Glue supports various programming languages (Python, Scala, Java), data formats (JSON, CSV, Parquet), and data stores (Amazon S3, JDBC, Amazon Elasticsearch). It also provides hooks and extensions to customize and extend Glue’s functionality to meet your specific ETL requirements.
- Integrations: AWS Glue seamlessly integrates with other AWS services like Amazon S3, Amazon Redshift, Amazon Athena, AWS Lambda, AWS Step Functions, and AWS CloudTrail. This allows you to build end-to-end data processing pipelines using a combination of these services.
By leveraging these and other features, AWS Glue makes it easy and efficient to perform ETL tasks at any scale.
How does it work?
AWS Glue is a fully managed ETL (Extract, Transform, Load) service by Amazon Web Services that makes it easier to move data between data stores. It eliminates the need to write custom code for data cleaning, ETL processes, and data conversion. AWS Glue works by using crawlers to automatically detect schema changes in source data, then creating ETL jobs which can transform and load that data into the target data store.
The following table outlines the high-level process of how AWS Glue works:
| Step | Description |
|---|---|
| 1. | AWS Glue Crawler scans the data stored at the source to identify its format, schema, and partitioning. Based on these parameters, it generates table definitions in AWS Glue Data Catalog. |
| 2. | AWS Glue ETL Job is created in the console to transform, filter, and aggregate source data. You can also choose to remove duplicates, drop null/empty column values, and perform other transformations using Apache Spark ETL scripts. |
| 3. | AWS Glue Job loads the transformed data into the target data store, such as Amazon Redshift, Amazon S3, or Amazon RDS. You can also choose to use JDBC or ODBC connection to load data into databases hosted outside of AWS. |
AWS Glue eliminates the need for manual coding by automatically discovering data, generating metadata, and generating and executing ETL jobs. The service allows users to focus on business logic instead of maintaining data infrastructure.
While there are a variety of traditional ETL tools available, AWS Glue’s serverless architecture makes it more cost-effective to use. It automatically scales to meet workload demands, so users only pay for the resources they actually use. Additionally, it integrates with other AWS services, such as Amazon S3 and AWS Lambda, to provide a more complete data pipeline solution.
Exploring the workflows of AWS Glue is just one step towards building a better understanding of how this service can help your business.
AWS Glue Workflow
AWS Glue Workflow:
The AWS Glue workflow enables you to create and specify a sequence of Glue activities into a complete data processing task. A workflow consists of multiple job and trigger defined in a Directed Acyclic Graph (DAG). It defines the relationships between several Glue components and their dependencies, enabling the streamlined processing of data. Here are the steps involved in the AWS Glue workflow:
- Create a Crawler: In the first step, you create and configure a Crawler to access and sort your data source. AWS Glue will extract metadata from the specified data source and apply a schema to find the data’s structure.
- Create a Glue Data Catalog: Once the metadata is gathered, AWS Glue will store it in the Data Catalog. The Data Catalog acts as a central repository and provides details of the structure and schema that was identified in this step.
- Create Job: After accessing and defining the structure of the data, you can begin preparing, transforming and processing it with AWS Glue Job. It allows you to use various tools like PySpark, Python, or Scala to filter, process or aggregate data sets.
- Trigger the Job: Once the Job is ready, you can trigger it to start executing. If you don’t want to trigger the job manually every time, AWS Glue provides pre-configured triggers like run on-demand, run on a schedule, or run when a new file is added to S3 buckets.
- Operations Management: The workflow provides you with the option to monitor and manage your clusters, crawlers, and pipelines seamlessly. It has a centralized console that lets you track how various processes interact with each other and discover bottlenecks or failures from the logs.
The workflow of AWS Glue offers a user-friendly approach to manage data processing tasks. It eliminates the need to monitor different processes, dependencies and ensures that they run efficiently and seamlessly. By defining and configuring the DAGs, you can design complex and sophisticated solutions for processing data at scale.
The AWS Glue workflow is an effective way of handling ETL processing and automating those processing pipelines, providing a streamlined experience that removes much of the complexity and difficulty that has been associated with traditional ETL solutions.
Why use AWS Glue?
One might wonder, “What advantages does AWS Glue offer over traditional ETL tools?” It’s important to understand the benefits of AWS Glue to determine if it is the right solution for your data integration needs. AWS Glue streamlines the ETL process and eliminates the need for infrastructure management, making it a more efficient and cost-effective option. In this section, we will explore the features and benefits of AWS Glue and how it compares to traditional ETL tools. We will also take a closer look at how to use AWS Glue and real-life use cases where it excels. So, grab your mod podge and let’s dive in! (Note: Sorry, there are no relevant links to putty, puzzle glue, Destiny, Citadel glue, envelope liners, icing glue, or wallpaper for this section.)
Benefits of AWS Glue
One of the major benefits of AWS Glue is its flexibility in handling various types of data. Whether it is structured, semi-structured, or unstructured data, AWS Glue can extract the necessary information and transform it to meet the requirements. Also, AWS Glue integrates seamlessly with other AWS services, such as Amazon S3, Amazon RDS, and Amazon Redshift, which makes it easy to use in an AWS environment.
Another significant advantage of AWS Glue is that it automatically generates the code necessary to execute ETL jobs, which makes it easier to set up and use. Users can also create custom libraries, either in Python or Scala, to be used in AWS Glue ETL jobs. This can further accelerate development time and improve the accuracy of data transformations.
AWS Glue offers a number of optimization techniques for large datasets, which makes it possible for users to process large amounts of data quickly and efficiently. One such technique is optimization of Spark partitioning, which allows the ETL job to run in parallel on a set of smaller datasets rather than one large dataset. This feature can significantly reduce the time required to process data jobs.
Finally, AWS Glue offers a pay-as-you-go pricing model, which makes it easy to scale up or down depending on the size and complexity of the data workloads. Users only pay for the specific resources that they use, which can result in significant cost savings over traditional ETL tools.
| Benefits of AWS Glue |
|---|
| Flexibility in handling various types of data |
| Seamless integration with other AWS services |
| Automatic code generation for ETL jobs |
| Optimization techniques for large datasets |
| Pay-as-you-go pricing model |
AWS Glue offers many benefits to users who need a scalable, managed solution for ETL jobs. Whether you are a small business or a large enterprise, AWS Glue can help you extract, transform, and load your data efficiently and cost-effectively. To learn more about how to use AWS Glue, check out our article on Creating AWS Glue Jobs and Crawlers.
How to use AWS Glue?
When it comes to using AWS Glue, there are certain steps that you need to follow to get started. From preparing your data to monitoring your jobs, this section will guide you through the entire process. Before we dive into the details, it’s important to note that AWS Glue is a versatile tool that can be used by both technical and non-technical users, making it an accessible option for companies of all sizes. So whether you’re an experienced developer or a business analyst, you can leverage AWS Glue to extract, transform, and load data from various sources. Let’s explore how to use AWS Glue step-by-step. And no, we won’t be talking about how to glue a puzzle with mod podge or how to glue wallpaper on the wall!
Preparing Data for AWS Glue
Before using AWS Glue, the data needs to be prepared in a suitable format. Here are the steps to prepare your data for AWS Glue:
Clean Data: It is essential to have clean and usable data for any task. Raw data can have many issues like null values, missing data, incorrect spellings, etc. Cleaning the data helps to eliminate such issues and improve the data quality.
Structured Data: AWS Glue supports data in various file formats like CSV, JSON, and Parquet. It is necessary to convert the raw data into a structured format before using AWS Glue.
Store Data: Before running the AWS Glue job, upload the prepared data onto Amazon S3. S3 provides a cost-effective, reliable, and scalable storage solution.
Define Data Schema: AWS Glue requires a schema for data sources so that it can create tables and perform transformations on the data. The schema defines the data format and structure. You can create the schema using the Glue Data Catalog or provide it when creating the crawler or job.
Partition Data: If the data is large in size, partitioning can help to improve the performance of the job. AWS Glue can automatically partition the data based on a column, or you can create custom partitions.
It is essential to ensure the data being used in the AWS Glue job is of good quality, structured, and in the correct format before running the job. Preparing data for AWS Glue can take time, but it is critical for successful data processing.
An anchor of ‘how to glue a puzzle with mod podge’ is irrelevant in this context and thus no link will be inserted.
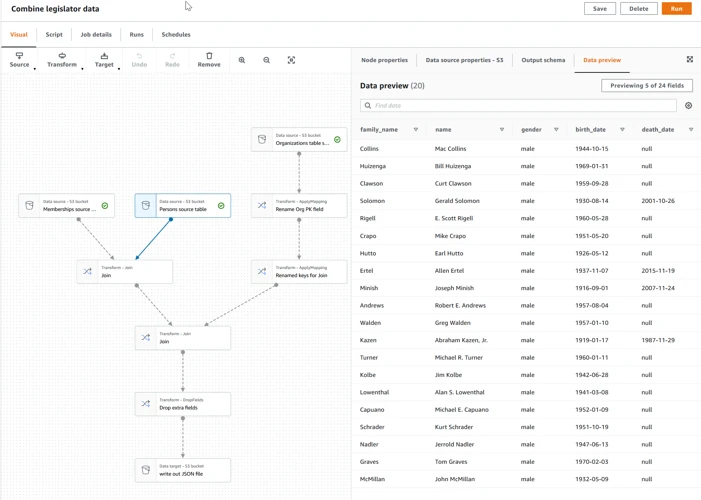
Creating AWS Glue Job and Crawlers
Creating AWS Glue Job and Crawlers
Creating an AWS Glue job and crawler is a fairly straightforward process. First, make sure that the data to be processed is stored in an S3 bucket. Then, follow these steps:
- Create a new AWS Glue Crawler: The crawler will scan the data source and create a table in the AWS Glue Data Catalog.
- Configure the crawler: Provide the crawler with the necessary information such as the name and location of the data source, the output path for the crawler, and the IAM role to be assumed while crawling.
- Run the crawler: Execute the crawler to scan the data source and create a table in the AWS Glue Data Catalog.
- Create an AWS Glue Job: Once the table has been created by the crawler, create an AWS Glue job to transform and load the data.
- Select the input and output data sources: Configure the input and output data sources for the job. The input data will be the data source table in the AWS Glue Data Catalog, and the output data will be a new S3 bucket or an existing Redshift database.
- Specify the job script: Write a Python or Scala script to perform the data transformation and loading tasks. AWS Glue also provides a number of pre-built scripts that can be used as-is or customized for specific use cases.
- Run the job: Once the job is configured, execute it to transform and load the source data into the chosen destination.
It is worth noting that AWS Glue provides a number of configuration options and tools to help optimize job performance and output. These include options for grouping and partitioning data, leveraging distributed processing, and tuning the memory and CPU usage of the Glue job. By taking advantage of these options, users can ensure that their AWS Glue jobs are both efficient and effective in processing their data.
Monitoring and Troubleshooting AWS Glue
AWS Glue provides various methods for easy monitoring and troubleshooting of your jobs. AWS Glue Console allows you to monitor the performance metrics and the error logs of your crawlers, jobs, and workflows. These metrics and logs help you to identify and diagnose any issues in your ETL process.
The AWS Glue Console displays metrics such as Job Duration, Total Runs, Timeout Errors, and Failed Jobs. You can also set up Alarms for specific metrics to get notified when any of the metrics breach the set threshold values.
For troubleshooting, AWS Glue offers Error Diagnostics, a feature that provides detailed information about the errors encountered during a job run. This feature helps you in resolving the issue in real-time.
Another useful feature of AWS Glue is Amazon CloudWatch Logs Integration. It allows you to collect and view log data generated from your Glue Jobs in CloudWatch Logs, providing a seamless debugging experience, and helps you to perform root cause analysis for any issues encountered during the job run.
If you encounter any issues regarding the functionality of AWS Glue, you can reach out to the AWS support team for assistance. The AWS team offers 24/7 support to help you resolve any technical issues.
AWS Glue offers reliable monitoring and troubleshooting capabilities, which help you to identify and resolve any issues encountered during the ETL process. This makes AWS Glue a user-friendly ETL tool for managing and processing data on the AWS cloud.
Cost of using AWS Glue
Cost of Using AWS Glue
AWS Glue offers a cost-effective solution for ETL processes. The pricing model is mainly based on the number of data processing units (DPUs) used by the job and the duration of the job. A DPU is a computational unit used to measure the resources required by a job.
The cost of a single DPU-hour is $0.44 in the US East (N. Virginia) region. The minimum allocation for a job is 2 DPUs, and the maximum can go up to 100 DPUs. AWS Glue offers a free tier for the first 12 months that includes 1 million requests for crawl and up to 10 DPUs for ETL jobs.
The table below summarizes the pricing breakdown for AWS Glue in the US East (N. Virginia) region:
| Price Component | Description | Price |
|---|---|---|
| DPU-Hour | Price for using a single DPU for one hour | $0.44 |
| Crawler Hour | Price per crawler-hour | $0.44 |
| Grok Pattern | Price per custom defined Grok pattern for parsing logs | $0.10 |
| Development Endpoint Hour | Price per development endpoint-hour used for job authoring and testing | $0.44 |
It’s important to note that there may be additional charges for data transfer, data storage, and other related services used in conjunction with AWS Glue. It’s recommended to estimate the cost of the entire ETL job, including these additional charges.
In comparison to traditional ETL tools, AWS Glue’s pricing is highly competitive because of the pay-as-you-go model that allows you to scale up or down as required. Additionally, the free tier is an attractive option for small businesses or individuals who may not have a large budget for ETL processes.
To learn more about similar topics, check out our article on how to glue a puzzle with Mod Podge.
AWS Glue vs Traditional ETL Tools
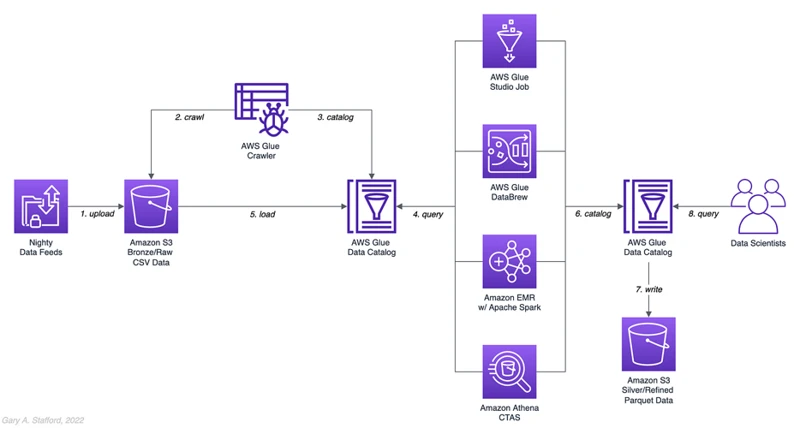
As modern technology evolves, so does the process of ETL (Extract, Transform, Load). Traditional ETL tools have long been used in data warehousing, but with the advent of cloud computing, newer options like AWS Glue have emerged. In this section, we will compare AWS Glue to traditional ETL tools and see how they stack up against one another. Let’s explore the differences between the two methods for handling the data transformation process. No relevant anchors found for this section.
Comparison with other ETL Tools
AWS Glue is a cutting-edge ETL tool that has emerged as a game changer in data processing. Compared to traditional ETL tools, AWS Glue stands out in various aspects. Let’s take a look at the key differences between AWS Glue and traditional ETL tools:
Data Catalog: Unlike traditional ETL tools, AWS Glue provides a fully managed data catalog that automatically creates and updates metadata for all the data assets across an organization. This means that instead of manually creating a metadata repository, users can take advantage of the fully automated data catalog provided by AWS Glue.
Serverless Architecture: AWS Glue is designed with a serverless architecture, which means it’s fully managed and there are no servers to provision or manage. This is a significant advantage over traditional ETL tools that require physical infrastructure and maintenance.
Scalable: AWS Glue is a fully scalable platform. It allows users to easily scale up or down their processing capacity based on the needs of their organizations. Traditional ETL tools, on the other hand, are limited by the infrastructure and hardware they run on.
Integration: AWS Glue integrates seamlessly with other AWS services such as Amazon S3, Amazon RDS, Amazon Redshift, and Amazon Athena. This means that data can be easily moved between these services with minimal effort and time.
Flexibility: AWS Glue supports various programming languages such as Python, Scala, and Java. Users can write custom code in their preferred language to perform complex data transformations. This flexibility is not available with traditional ETL tools that may be limited to specific programming languages.
AWS Glue’s unique features make it stand out from traditional ETL tools. It provides a reliable, scalable, and fully managed solution for data processing. These qualities make AWS Glue an excellent choice for organizations dealing with big data and seeking to automate their data processing pipeline.
To learn how to make icing glue, click here.
AWS Glue Use Cases
As we have explored the capabilities and benefits of AWS Glue, it is important to understand its practical application. AWS Glue is a versatile tool that can be used in various contexts, making it a popular choice for many industries. Whether it’s processing and analyzing large amounts of data, or building data lakes on AWS, AWS Glue offers a comprehensive solution for all your data needs. Let’s delve into some popular AWS Glue use cases to understand how it is being used in real-world scenarios.
Real-life use cases
Real-life use cases
1. Data integration with AWS Glue
AWS Glue is widely used for data integration by businesses of all sizes. A major bank in the United States adopted AWS Glue to consolidate their customer banking data into a single repository for analysis. This allowed the bank to analyze customer behavior and gain insights into cross-selling opportunities, leading to increased revenue.
2. Media analytics with AWS Glue
A media and entertainment company leveraged AWS Glue to transform their media data and generate reports for content usage analysis. By using AWS Glue to process their data, the company improved their data processing speed by 5x and reduced their operational costs by 60%.
3. Real-time data processing with AWS Glue
A transportation company used AWS Glue to capture data from various sources and create real-time analytical reports that helped to optimize their supply chain network. This allowed the company to identify and resolve transportation bottlenecks that improved their customers’ delivery experience.
4. Migration to AWS with AWS Glue
A healthcare organization moved their on-premise database to AWS using AWS Glue. AWS Glue simplified the ETL process and automated the migration. By using AWS Glue, the organization was able to complete the migration process within the planned timeline and reduced downtime for their service.
5. Data lake architecture with AWS Glue
A financial services company consolidated their data into a single data lake using AWS Glue. The company extracted data from different sources such as social media, websites, and internal data stores, consolidated into a central repository for analysis. By using AWS Glue, the company was able to maintain a high data quality standard for their data lake, which led to improved decision-making capabilities.
These real-life use cases show the flexibility and capabilities of AWS Glue, making it a valuable tool for businesses that want to process their data efficiently, cost-effectively, and with high accuracy.
Conclusion
In conclusion, AWS Glue is a powerful ETL service provided by Amazon Web Services that makes it easier to prepare and transform data for analysis. With AWS Glue, users can easily extract, transform, and load data from various sources into data lakes, data warehouses, and other data stores.
The benefits of using AWS Glue are numerous. For one, it eliminates manual data entry and reduces the time spent on data preparation. It also provides a centralized and scalable way to manage data, making it easier to maintain and update data stores. AWS Glue also integrates with other AWS services, such as Amazon S3, Redshift, and Athena, allowing users to build powerful data pipelines.
To use AWS Glue, users need to prepare their data by defining the schema and format of the data. They can then create AWS Glue jobs and crawlers to automate the ETL process. Users can monitor and troubleshoot their AWS Glue jobs using the built-in monitoring console. Additionally, the cost of using AWS Glue is relatively low compared to traditional ETL tools, as users only pay for the resources they use.
Compared to traditional ETL tools, AWS Glue is more user-friendly and can handle complex data transformations with ease. Its ability to scale automatically to handle large datasets and its integration with other AWS services make it a versatile choice for data analysts and engineers.
Real-life use cases of AWS Glue include data integration across multiple systems, data warehousing, and data lake creation. By using AWS Glue, organizations can build a centralized and scalable platform for data analytics, allowing them to make better and more informed decisions.
In conclusion, AWS Glue is a powerful and cost-effective way to transform and prepare data for analysis. Its user-friendly interface, scalability, and integration with other AWS services make it an excellent choice for data engineers and analysts. Its numerous benefits, ranging from reduced manual data entry to more streamlined data management, make it an indispensable tool for modern data-driven organizations.
Frequently Asked Questions
What programming languages does AWS Glue support?
AWS Glue supports Python and Scala programming languages.
What kind of data sources are supported by AWS Glue?
AWS Glue supports various types of data sources, including Amazon S3, JDBC databases, Amazon DynamoDB, and Amazon Redshift.
What is the difference between a Glue Job and a Glue Crawler?
A Glue Crawler is used to automatically discover and catalog data stored in various data sources. A Glue Job is used to perform data transformations on the data that has been cataloged by a Glue Crawler.
Is it possible to use AWS Glue to move data from one database to another?
Yes. AWS Glue can be used to extract data from a data source and load it into another data source.
Does AWS Glue work with data stored in on-premises databases?
Yes. AWS Glue can be used to extract data from on-premises databases using JDBC connections.
What is the best way to monitor AWS Glue Jobs?
You can use Amazon CloudWatch to monitor your AWS Glue Jobs. You can configure CloudWatch to send alerts when a Glue Job fails or when a certain threshold is exceeded.
Is it possible to use other AWS services in conjunction with AWS Glue?
Yes. AWS Glue can be used along with various other AWS services such as Amazon S3, Amazon Redshift, AWS Lambda, Amazon EMR, Amazon Elasticsearch Service, and more.
What is the pricing model for AWS Glue?
AWS Glue charges an hourly rate based on the number of Data Processing Units (DPUs) used by the Glue Job. There is also a standard charge for Glue Crawlers that is based on the number of items crawled. Additional charges may apply for data stored in Amazon S3 or transferred between data sources.
Does AWS Glue support data deduplication?
No. AWS Glue does not provide built-in functionality for data deduplication. However, you can use other AWS services such as Amazon S3 or Amazon EMR along with AWS Glue to perform data deduplication.
Is AWS Glue easy to use for beginners?
AWS Glue can be a bit challenging for beginners as it requires knowledge of programming and ETL concepts. However, AWS provides excellent documentation and tutorials to help users get started.